香港服务器redis慢(香港服务器慢怎么办)

今天给各位分享香港服务器redis慢的知识,其中也会对香港服务器慢怎么办进行解释,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:
Redis有哪些慢操作?
从业务服务器到Redis服务器这条调用链路中变慢的原因可能有2个
但是大多数情况下都是Redis服务的问题。但是应该如何衡量Redis变慢了呢?命令执行时间大于1s,大于2s?这其实并没有一个固定的标准。
例如在一个配置较高的服务器中,0.5毫秒就认为Redis变慢了,在一个配置较低的服务器中,3毫秒才认为Redis变慢了。所以我们要针对自己的机器做基准测试,看平常情况下Redis处理命令的时间是多长?
我们可以使用如下命令来监测和统计测试期间的最大延迟(以微秒为单位)
比如执行如下命令
参数中的60是测试执行的秒数,可以看到最大延迟为3725微秒(3毫秒左右),如果命令的执行远超3毫秒,此时Redis就有可能很慢了!
那么Redis有哪些慢操作呢?
Redis的各种命令是在一个线程中依次执行的,如果一个命令在Redis中执行的时间过长,就会影响整体的性能,因为后面的请求要等到前面的请求被处理完才能被处理,这些耗时的操作有如下几个部分
Redis可以通过日志记录那些耗时长的命令,使用如下配置即可
执行如下命令,就可以查询到最近记录的慢日志
之前的文章我们已经介绍了Redis的底层数据结构,它们的时间复杂度如下表所示
名称 时间复杂度 dict(字典) O(1) ziplist (压缩列表) O(n) zskiplist (跳表) O(logN) quicklist(快速列表) O(n) intset(整数集合) O(n)
「单元素操作」 :对集合中的元素进行增删改查操作和底层数据结构相关,如对字典进行增删改查时间复杂度为O(1),对跳表进行增删查时间复杂为O(logN)
「范围操作」 :对集合进行遍历操作,比如Hash类型的HGETALL,Set类型的SMEMBERS,List类型的LRANGE,ZSet类型的ZRANGE,时间复杂度为O(n),避免使用,用SCAN系列命令代替。(hash用hscan,set用sscan,zset用zscan)
「聚合操作」 :这类操作的时间复杂度通常大于O(n),比如SORT、SUNION、ZUNIONSTORE
「统计操作」 :当想获取集合中的元素个数时,如LLEN或者SCARD,时间复杂度为O(1),因为它们的底层数据结构如quicklist,dict,intset保存了元素的个数
「边界操作」 :list底层是用quicklist实现的,quicklist保存了链表的头尾节点,因此对链表的头尾节点进行操作,时间复杂度为O(1),如LPOP、RPOP、LPUSH、RPUSH
「当想获取Redis中的key时,避免使用keys *」 ,Redis中保存的键值对是保存在一个字典中的(和Java中的HashMap类似,也是通过数组+链表的方式实现的),key的类型都是string,value的类型可以是string,set,list等
例如当我们执行如下命令后,redis的字典结构如下
我们可以用keys命令来查询Redis中特定的key,如下所示
keys命令的复杂度是O(n),它会遍历这个dict中的所有key,如果Redis中存的key非常多,所有读写Redis的指令都会被延迟等待,所以千万不用在生产环境用这个命令(如果你已经准备离职的话,祝你玩的开心)。
「既然不让你用keys,肯定有替代品,那就是scan」
scan是通过游标逐步遍历的,因此不会长时间阻塞Redis
「用用zscan遍历zset,hscan遍历hash,sscan遍历set的原理和scan命令类似,因为hash,set,zset的底层实现的数据结构中都有dict。」
「如果一个key对应的value非常大,那么这个key就被称为bigkey。写入bigkey在分配内存时需要消耗更长的时间。同样,删除bigkey释放内存也需要消耗更长的时间」
如果在慢日志中发现了SET/DEL这种复杂度不高的命令,此时你就应该排查一下是否是由于写入bigkey导致的。
「如何定位bigkey?」
Redis提供了扫描bigkey的命令
可以看到命令的输入有如下3个部分
这个命令的原理就是redis在内部执行了scan命令,遍历实例中所有的key,然后正对key的类型,分别执行strlen,llen,hlen,scard,zcard命令,来获取string类型的长度,容器类型(list,hash,set,zset)的元素个数
使用这个命令需要注意如下两个问题
「如何解决bigkey带来的性能问题?」
我们可以给Redis中的key设置过期时间,那么当key过期了,它在什么时候会被删除呢?
「如果让我们写Redis过期策略,我们会想到如下三种方案」
定时删除策略对CPU不友好,当过期键比较多的时候,Redis线程用来删除过期键,会影响正常请求的响应
惰性删除读CPU是比较有好的,但是会浪费大量的内存。如果一个key设置过期时间放到内存中,但是没有被访问到,那么它会一直存在内存中
定期删除策略则对CPU和内存都比较友好
redis过期key的删除策略选择了如下两种
「惰性删除」 客户端在访问key的时候,对key的过期时间进行校验,如果过期了就立即删除
「定期删除」 Redis会将设置了过期时间的key放在一个独立的字典中,定时遍历这个字典来删除过期的key,遍历策略如下
「因为Redis中过期的key是由主线程删除的,为了不阻塞用户的请求,所以删除过期key的时候是少量多次」 。源码可以参考expire.c中的activeExpireCycle方法
为了避免主线程一直在删除key,我们可以采用如下两种方案
Redis是一个内存数据库,当Redis使用的内存超过物理内存的限制后,内存数据会和磁盘产生频繁的交换,交换会导致Redis性能急剧下降。所以在生产环境中我们通过配置参数maxmemoey来限制使用的内存大小。
当实际使用的内存超过maxmemoey后,Redis提供了如下几种可选策略。
「Redis的淘汰策略也是在主线程中执行的。但内存超过Redis上限后,每次写入都需要淘汰一些key,导致请求时间变长」
可以通过如下几个方式进行改善
Redis的持久化机制有RDB快照和AOF日志,每次写命令之后后,Redis提供了如下三种刷盘机制
「当aof的刷盘机制为always,redis每处理一次写命令,都会把写命令刷到磁盘中才返回,整个过程是在Redis主线程中进行的,势必会拖慢redis的性能」
当aof的刷盘机制为everysec,redis写完内存后就返回,刷盘操作是放到后台线程中去执行的,后台线程每隔1秒把内存中的数据刷到磁盘中
当aof的刷盘机制为no,宕机后可能会造成部分数据丢失,一般不采用。
「一般情况下,aof刷盘机制配置为everysec即可」
在持久化一节中,我们已经提到 「Redis生成rdb文件和aof日志重写,都是通过主线程fork子进程的方式,让子进程来执行的,主线程的内存越大,阻塞时间越长。」
可以通过如下方式优化
当机器的内存不够时,操作系统会将部分内存的数据置换到磁盘上,这块磁盘区域就是Swap分区,当应用程序再次访问这些数据的时候,就需要从磁盘上读取,导致性能严重下降
「当Redis性能急剧下降时就有可能是数据被换到Swap分区,我们该如何排查Redis数据是否被换到Swap分区呢?」
每一行Size表示Redis所用的一块内存大小,Size下面的Swap表示这块大小的内存,有多少已经被换到磁盘上了,如果这2个值相等,说明这块内存的数据都已经被换到磁盘上了
我们可以通过如下方式来解决
最后我们总结一下Redis的慢操作
")
Redis为什么会那么快?
最近学习了一下Redis写一篇文章来总结一下学习成果,学习的方式主要是看书,看的是Redis 5设计与源码分析;想系统学习的同学,可以好好看看很推荐这本书,那么,为什么标题选择Redis为什么会那么快?因为,我在学习的过程中,感受到Redis的精髓就是快,为了快这个属性,它有了很多自己特殊设计及实现;
Redis快,我主要是基于三大部分的理解
下面分别对这2,3部分进行展开:
首先,先要知道Redis工作线程是单线程的,但是,整个Redis来说,是多线程的;
Redis事件处理 :
Redis 服务器是典型的事件驱动程序,而事件又分为文件事件(socket 的可读可写事件)与时间事件(定时任务)两大类。已经注册的文件事件存储在event[]数组中, 时间事件形成链表;Redis 底层可以使用4中I/O多路复用模型(kqueue、epoll、select等)根据操作系统的不同选择不同, 关于,多路复用模型相关内容可以查看我的另一篇文章 操作系统IO进化史 所以,epoll本身就效率很高了;但是,随着我们网卡的不断升级,在Redis 6.0之后的版本中,对IO的处理变成了多线程;
为什么对IO的处理变成了多线程能提高速度?
下面是Redis6.0之前的情况:
如果到了Redis6.0之后:
所以,这也是Redis快的一个主要原因;
由于,Redis中设计的话,主要分为底层设计结构以及一些相应的功能,所以,特定将其分为2部分来进行讲解;
Redis底层数据结构有简单动态字符串,跳跃表,压缩列表,字典,整数集合;针对,简单动态字符串,压缩列表,主要是考虑到节约内存;像跳跃表,字典,主要是考虑到查询速度,整数集合即考虑到了空间又考虑到了时间;其实像字典中的渐进式rehash,以及间断key查找,都是考虑到了节约时间;具体的内容可以查看我的另一篇文章, Redis底层数据结构
具体细节可查看官网
优点:最多有25%的过期key存在内存中,这种方法会比轮询更加省时间;就是稍微牺牲内存,来保证 redis的性能,就是快; 还是以空间换时间的思想;
注意 :个人觉得这里和 缓存雪崩 还能建立其联系,如果,一个大型的redis实例中所有的key在同一时间过期了,那么,redis会持续扫描keys 因为,一直大于25%;虽然,这是有扫描时间的上限的25ms;这个时候,刚好客户端请求过来了,如果,客户端将超时时间设置的比较短,比如说10ms,那么就会出现大量链接因为超时而关闭,业务端也会出现很多异常。(客户端超时时间,如果说设置得太小,那么容易导致访问redis失败,如果,设置太大,那么,在redis异常的时候,不容易及时作出切换;一般是通过网络延迟和redis慢日志来进行查看的)
redis的特点是快,它虽然有事务,但是,它是没有回滚的,事务的功能是不够完善的; 回滚:代表失败时,回滚到事务开始的时刻;
redis 是单线程的 如果,有多个客户端,一个客户端的事务 并不会阻塞到其他客户端; 客户端1 发送 开启事务的标记 客户端2 也开启事务 。随着时间发展;2又连续发了一些命令 1 也发了一些命令; 这时候,会先看谁的执行指令先到; 假设 2 先到达,这个时候,先执行2 的相关数据,在执行1相关的命令; 如果 1 先到达,这个时候,先执行1 的相关命令,再执行2;
事务失败处理
这个时候,会发现报错那条语句不执行,剩下的语句都会进行执行;也没有发生了回滚;
证明 :redis是不支持事务回滚的。在运行期错误,即使事务中有某条/某些命令执行失败了,事务队列中的其他命令仍然会继续执行 -- Redis 不会停止执行事务中的命令;
为什么Redis 不支持事务回滚?
总结 :Redis为了快,而不支持事务回滚;
在redis中,有两个东西 第一个为RDB , 第二个为AOF RDB为快照/副本相关内容, AOF为日志相关的内容;
RDB的特点 :1.需要时点性 (比如说:我有1G的内存,需要持久化到硬盘,比如说:一个小时持久化一次。那么,假设在8点,就需要进行持久化)
如何实现RDB持久化呢?
方法一:阻塞Redis ,Redis不再对外提供服务了,但是,这种方式是需要阻塞的,很显然,如果,这个持久化需要花费1s,那么,这个时候,Redis 不能被客户端进行使用;
方法二:非阻塞 Redis继续对外提供服务;
但是,这个时候会出现一个问题;比如说:8点开始RDB持久化,8点零1秒才持久化完,问题就来了:持久化的数据是8点的还是8点零1秒的呢?很显然,是8点的;那么,在8点到8点零1秒这个过程中,数据是会发生改变的,那么, 怎么解决这个数据不一致的问题呢? 比如说:8点的时候,b = 10 到 8点零1秒的时候,b =20;
为了解决这个读写并存 使用CopyOnWrite 的思想来进行实现;
就是,在操作系统中,先使用fork() 创建子线程来复制一份副本(注意:这里拷贝的是指针,所以,速度会很快)然后,这个副本,就保持在8点不变了。然后,复制的时候,就复制这份副本就行了,对数据增删改查就在父进程中更改。
但是,因为父子进程都指向的是同一个内存,所以,不能在这个内存中改,比如说:不能在原来key 8 中进行更改,比如说要改key = 10 那么,就得在内存中,再创建一块区域,然后,让父进程中指针指向新的key ,这样两个进程就不会相互影响了。
这里也验证了Redis是多线程的;
具体实现:
RDB的缺点
RDB的优点 :恢复数据的速度相对较快;
Redis内存大小选择 进程一般使用10G以内,因为从内存到磁盘持久化这个过程,如果说,10G需要写的时间比较久,那么,如何解决呢?1. 减少内存 2. 硬盘选择固态硬盘;
针对RDB容易丢失数据的问题,提出了AOF持久化机制
AOF : append on File 向文件中,进行追加;redis发生写操作时,会记录到文件中;
优点 :1.丢失的数据比较少
背景 :RDB和AOF可以同时开启,如果,开启了AOF只会用AOF来进行恢复,即便RDB也开启了,也不会使用它;因为,AOF的修复比较准确;但是,AOF是比较慢的,所以,在4.0以后,AOF就包含了RDB全量,和增加的新的写操作。这样来提高速度;
缺点 :由于,AOF是增加的方式,所以,如果一直增加的话,就会有 1.体量无限变大 2.恢复慢 的缺点;为了解决这个问题,需要设计出一个方案让日志AOF足够小;这个,就有了 重写 的方案;4.0之前,重写方案是将AOF进行瘦身,比如说:把创建key和删除key的命令进行抵消删除;4.0之后,就采用 混合持久化 比如说:我这个AOF已经到了100M文件了,这个时候,我先将老的数据变成RDB文件(二进制文件)然后,再存储到AOF中,再将增量以指令的方式Append 到AOF。所以,是一个混合体;这里的AOF日志不再是全量的日志,而是持久化开始到持久化结束这段时间的增量AOF日志通常很小;那么,它这么改变的 优点 是:在Redis重启时,可以先加载RDB的内容,在加载增量AOF日志,完全替代AOF全量日志重放,重启的效率将大幅度提升; 每次一重写完,就会变成RDB ;
脏数据刷入时机 :AOF日志是以文件形式存在的,当程序对AOF日志进行写操作时, 实际上是先将数据写到一个内存缓存中,然后,让内存再把脏数据写回到磁盘中 那么,什么时候写呢?如果,还没来的及写就宕机了,那么可能会出现日志丢失;这时候有三个级别可以调;
no : 不调用fsync 等到它满了再进行调用(fsync 可以将指定文件的内容,强制从内核缓存刷到磁盘) 一般生产环境不用
always :每写了一个数据,就调用一次fsync 一般生产环境不用
everysec: redis每一秒调用一次flush
一般Redis 的主节点不会进行持久化操作,持久化操作主要是在从节点中进行。因为,没有来自客户端请求的压力;
上面是Redis持久化的两种方式 由于,持久化过程需要花费的时间是比较多的,所以,一般由从节点来进行持久化操作; 主服务器发现需要执行完整重同步时,会fork子进程执行RDB持久化,并将持久化数据发送给从服务器。这时候,有两种选择 1. 直接通过Socket发送给从服务器(从服务器支持eof),2. 持久化数据到本地文件,待持久化完毕后再将该文件发送给从服务器。 默认第二种,具体情况是根据同步信息确定;但是,第一种效率会更高,速度会更快;
总结 :为了Redis快的特性,Redis在持久化的时候,使用fork()函数,新开线程来执行;同时,如果主从服务器的话,还提供了psync2来进行部分重同步;eof功能;
redis的特点就是快,在系统设计的方方面面都体现了这个快的特性;这是我自己在学习Redis相关知识时,了解到的内容,做个记录。如果,有偏差欢迎读者进行指正!
java连接redis超时问题怎么解决
应该是redis本身的服务有问题了
本文所针对的连接超时问题所涉及的相关元素如下:
Redis客户端: Jedis (java)
Redis版本 :2.8.12
Redis部署操作系统类型:Linux
正文开始:
No 1.Redis执行大命令(时间复杂度为O(N)的命令)
问题剖析:
a.Redis服务器端通过单线程处理命令,一旦有大命令被执行,Redis将无法及时响应来自客户端的任何命令
关于Redis大命令的监控,可以查看slowlog来观察
b.在使用jedis作为redis客户端时,当redis连接池的配置参数testOnBorrow=true时,默认会在获取redis连接
时,先执行redis的ping方法,而基于原因a,此时redis将无法及时响应,自然会报出time out异常
如何解决:
a.尽量避免使用时间复杂度为O(N)的命令
b.如果无法避免使用时间复杂度为O(N)的命令,则应降低其使用频率,避免在业务高峰期时使用
No 2.Redis单次操作数据包过大
问题分析
a.单次操作数据包过大,且操作频繁,极有可能会导致网络拥堵
b.在使用jedis作为redis客户端时,当redis连接池的配置参数testOnBorrow=true时,默认会在获取redis连接
时,先执行redis的ping方法,而基于原因a,此时redis将无法及时响应,自然会报出time out异常
如何解决:
a.排查代码,确定是否存在大数据(数据条目过多/单条数据过大)操作,将其进行改造,改造方案有两个:
a1.数据拆分,变更数据类型(常见的情况是将java中的collection类型序列化后存入redis的String数据
类型中),如将String数据类型调整为hash/list/set等,这常用于解决单条数据量过大的情况
a2.调整业务逻辑,减少单次数据查询范围(常见的情况如将redis中的整个hash数据取回,在应用程序内存中获取需要的entry),如使用hget等单条查询命令替换hgetall命令
redis读写瓶颈
从你这个描述来看,写性能确实不太正常。
我有一种方法可以用来看一下你这50000条数据是不是超过了默认的maxmemory值:
统计一下10000条数据大约占的内存值,估计5W条记录的大约内存值,然后再看一下你的VM是否开启。这样做是因为超过了指定的内存同时没开启vm时,有可能会导致进程挂掉。
你既然使用了默认配置,你还可以看一下日志里是不是会有崩溃记录。也可以根据记录找一下其他的原因。
你用的是hash结构的话,可以调整一下hash-zipmap-max-entries这个参数。一般这个参数在1000的时候性能是比较高的。超过1000以后CPU就上来了。默认是512.
如何解决redis高并发客户端频繁time out
redis为什么会有高并发问题
redis的出身决定
Redis是一种单线程机制的nosql数据库,基于key-value,数据可持久化落盘。由于单线程所以redis本身并没有锁的概念,多个客户端连接并不存在竞争关系,但是利用jedis等客户端对redis进行并发访问时会出现问题。发生连接超时、数据转换错误、阻塞、客户端关闭连接等问题,这些问题均是由于客户端连接混乱造成。
同时,单线程的天性决定,高并发对同一个键的操作会排队处理,如果并发量很大,可能造成后来的请求超时。
在远程访问redis的时候,因为网络等原因造成高并发访问延迟返回的问题。
解决办法
在客户端将连接进行池化,同时对客户端读写Redis操作采用内部锁synchronized。
服务器角度,利用setnx变向实现锁机制。
关于香港服务器redis慢和香港服务器慢怎么办的介绍到此就结束了,不知道你从中找到你需要的信息了吗 ?如果你还想了解更多这方面的信息,记得收藏关注本站。
本文由admin于2022-12-19发表在靑年PHP官网,如有疑问,请联系我们。
本文链接:https://qnphp.com/post/37966.html
相关文章
-
美国疫情最新数据消息,美国疫情最新数据消息2022年
-
西安疫情最新数据,西安疫情最新数据消息5分钟前封城
-
北京最新疫情,北京最新疫情大数据报告
-
阿里大数据官网,阿里的大数据有多可怕
-

如何进行品牌营销,如何进行品牌营销,将人才数据服务推广出去
-
数据分析软件工具有哪些,数据分析软件哪个最好用
-

爱链网中可以进行链接买卖,爱链科技有限公司
-
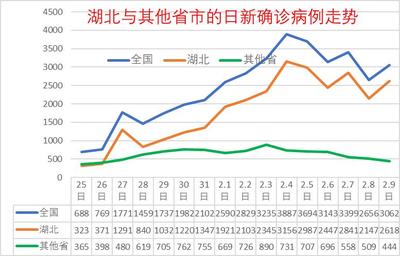
全国最新的疫情数据,现在什么病毒出现了


")
")
")




